.png)


Founded by Sri Raghu Malireddi & Harsha Nalluru
If you’ve ever built a conversational or voice AI product, you’ve felt it - that awkward pause when your agent lags or hesitates. The illusion of conversation breaks, and suddenly it feels less like talking to intelligence and more like waiting for a page to load.
The culprit is almost always retrieval. Every query hops across networks and cloud databases, adding seconds of delay. As usage scales, those small lags snowball into lost users, rising infra and egress costs. Teams spend weeks rebuilding embeddings and indexes, tuning search infra just to get “good enough” answers instead of focusing on what actually matters: building great AI experiences!
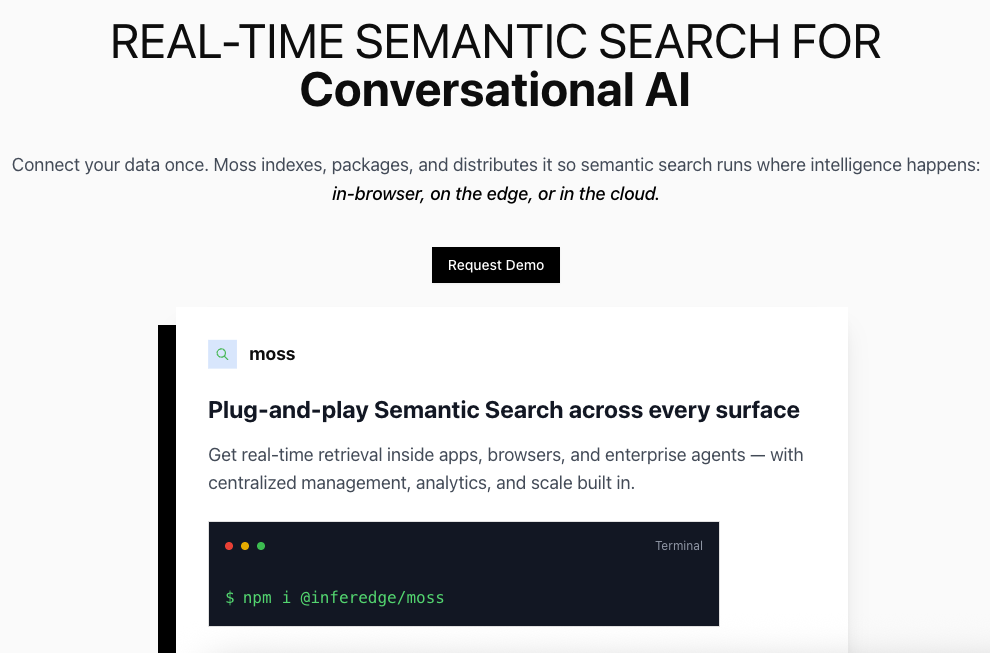
Moss puts real-time semantic search in the same runtime as your agent and application, so you can -
Moss founding team knew each other for 8+ years and bring deep expertise in machine learning, high-performance computing and developer experience.
Sri was an ML Lead at Grammarly and Microsoft, where he shipped LLMs and personalization systems used by millions of users across Office, Bing, and Grammarly. His work on personalization drove 300% retention growth for Grammarly Keyboard and scaling models to 40M+ DAUs. He has published at top ML conferences such as ACL and holds multiple patents in real-time ML.
Harsha was a Tech Lead @ Microsoft, where he architected the core stack of the Azure SDK, powering 400+ cloud services and 100M+ weekly downloads on npm. He also built foundational open-source tools and large-scale test automation systems. Earlier, ranked among the nation’s best in the Olympiads like the IMO and UCO, he combines analytical rigor with large-scale engineering expertise.
The idea for Moss came from their deep frustration with how slow “intelligent” systems actually felt in practice. While building large-scale agentic systems at Microsoft and Grammarly, they kept hitting the same wall - retrieval lag that made even the smartest models feel lifeless. Through evolution, humans are wired to expect instant replies; when AI hesitates, it breaks the illusion of intelligence. They started Moss to fix that by collapsing the multi-hop retrieval stack into a real-time, local-first runtime that lets AI think and respond at the speed of thought.
https://www.youtube.com/watch?v=7-PrunZVXTo
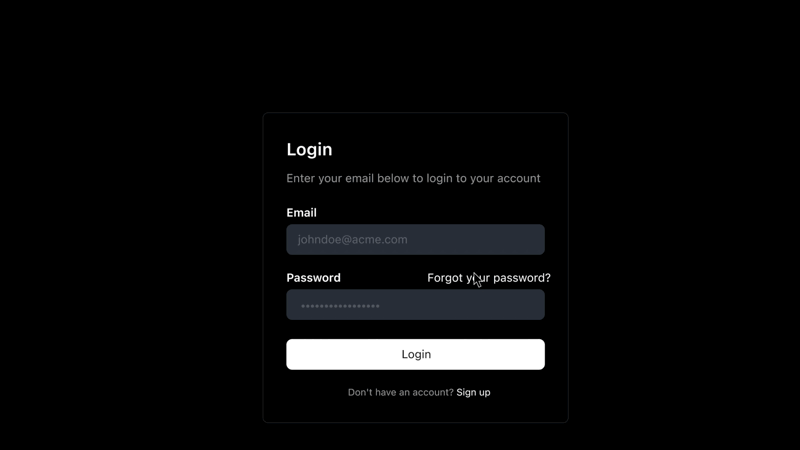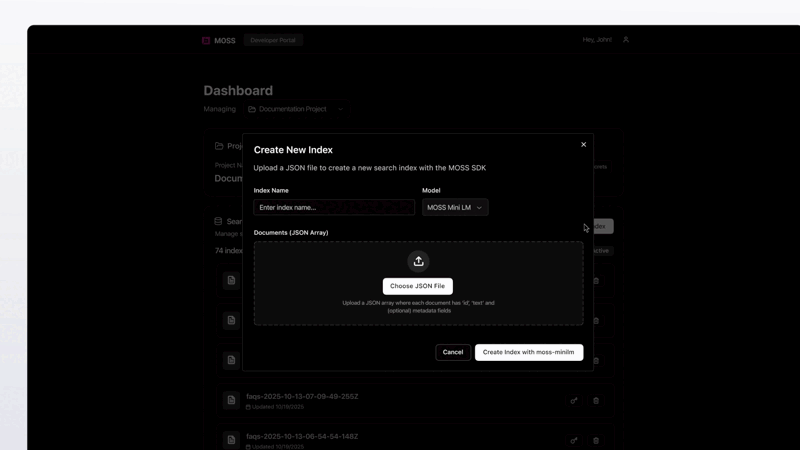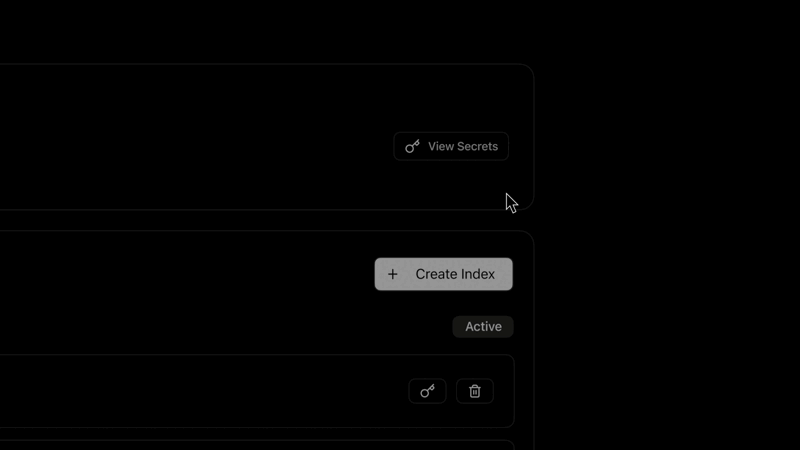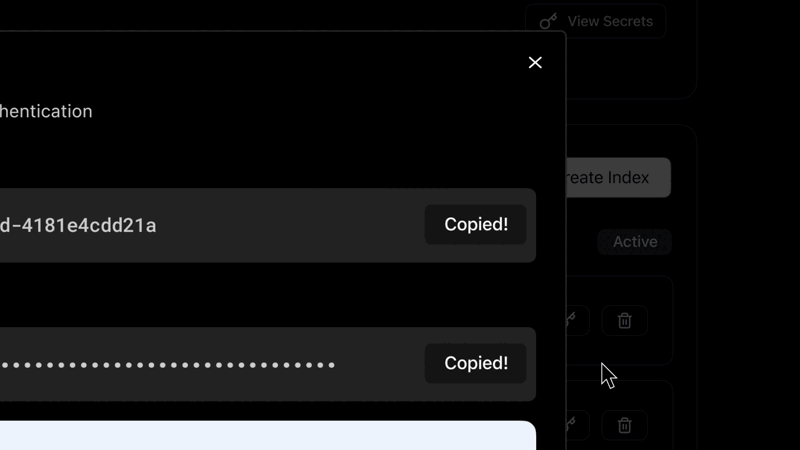
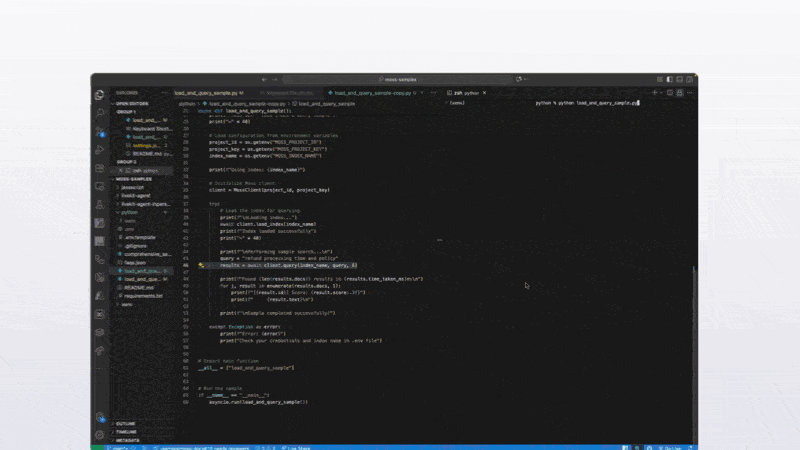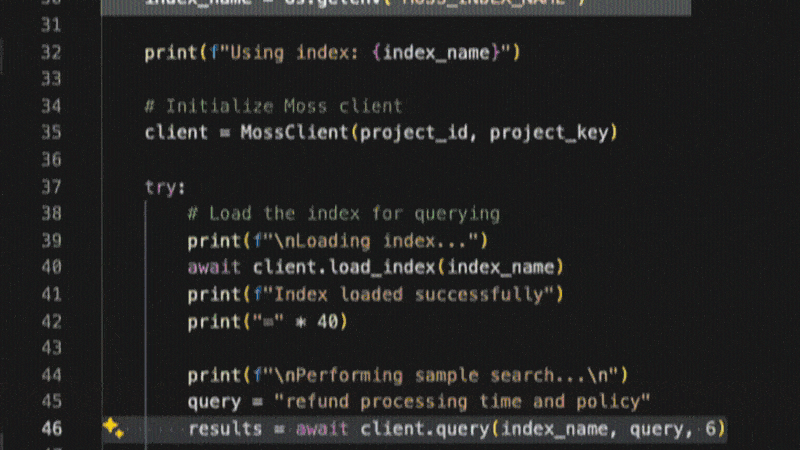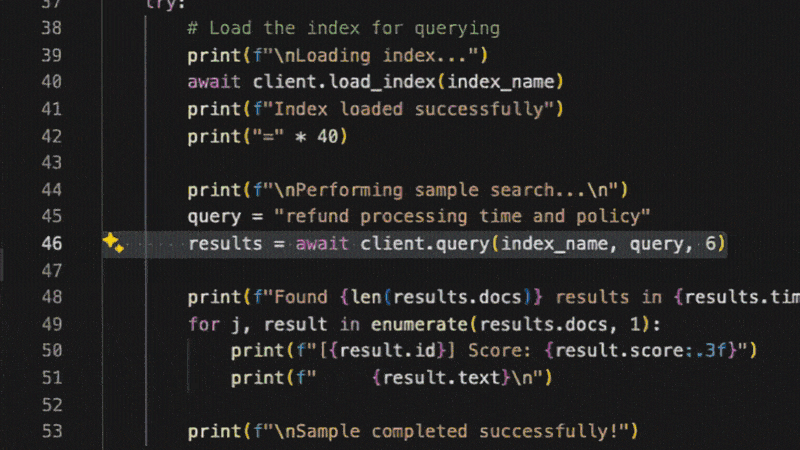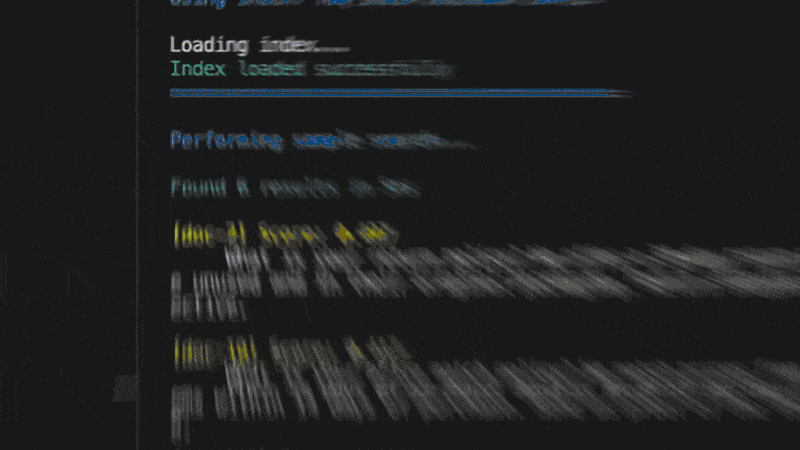
Using their SDKs - init, load and query indexes in sub-10ms.
They are seeing strong inbound pull from the market with 6 enterprise design partners and 3 paying customers actively building their products around Moss’s core tech, with 7 more actively evaluating. They are working closely with Voice AI orchestration companies like Pipecat (Daily.co) and LiveKit, embedding Moss at the core of their real-time retrieval and context pipelines. Usage and revenue have been growing ~100% week over week, and Moss is quickly becoming the foundational layer teams rely on to make AI feel instant, contextual, and truly responsive.
Contact information -
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Built for Delaware C-Corps. Trusted by 1,000+ startups.
Copyright © Fondo (BloomJoy, Inc.)




