.png)

RunAnywhere recently launched!

Founded by Sanchit Monga & Shubham Malhotra
Edge AI is inevitable — users want instant responses, full privacy (health, finance, personal data), and AI that actually works on planes, subways, or spotty rural connections.
But shipping it today is brutal:
Result: most teams either give up on local AI or ship a brittle, hacked-together experience.
RunAnywhere isn't just a wrapper around a model. It is a full-stack infrastructure layer for on-device intelligence.
1. The "Boring" Stuff is Built-in They provide a unified API that handles model delivery (downloading with resume support), extraction, and storage management. You don't need to build a file server client inside your app.
2. Multi-Engine & Cross-Platform They abstract away the inference backend. Whether it's llama.cpp or ONNX etc, you use one standard SDK.
3. Hybrid Routing (The Control Plane) They believe the future isn't "Local Only"—it's Hybrid. RunAnywhere allows you to define policies: try to run the request locally for zero latency/privacy; if the device is too hot, too old, or the confidence is low, automatically route the request to the cloud.
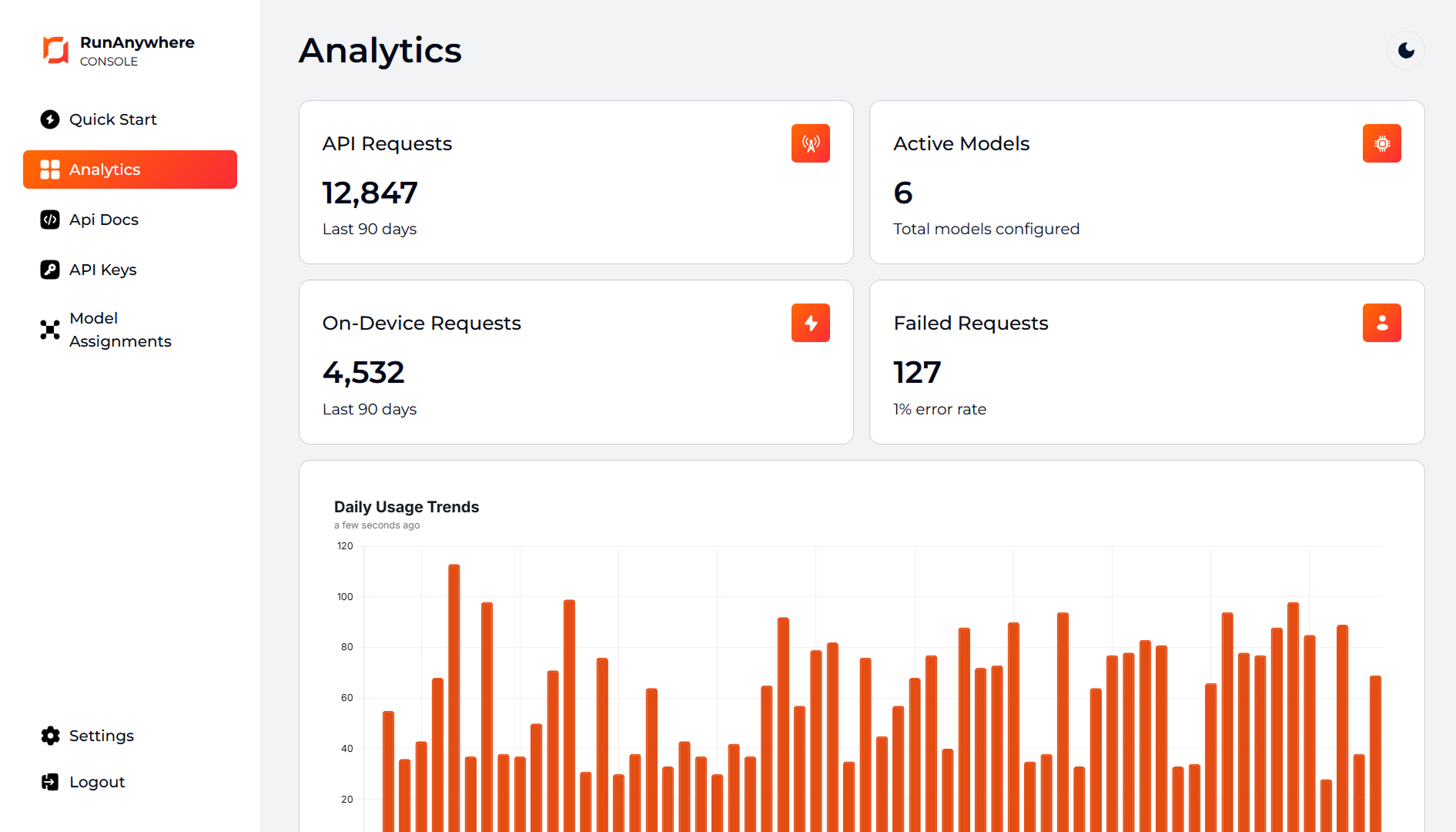
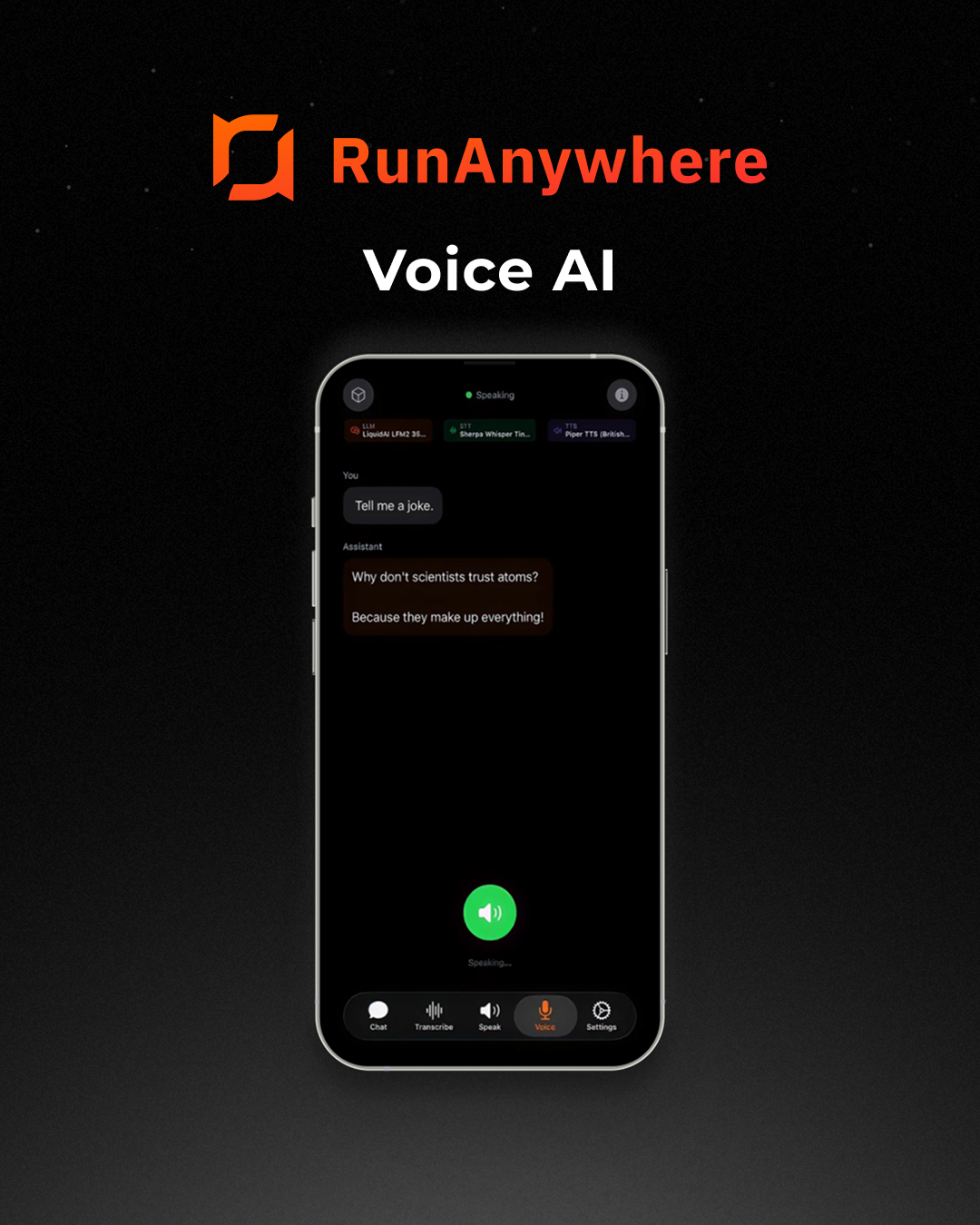
Try their demo apps:
They are in full execution mode post-launch and hunting design partners + early feedback:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Built for Delaware C-Corps. Trusted by 1,000+ startups.
Copyright © Fondo (BloomJoy, Inc.)




