.png)

WarpGrep by MorphLLM recently launched!

Founded by Tejas Bhakta
Coding agents don’t feel fast because they aren’t.
In their benchmarks, agents spend 60%+ of their time searching for the right code, not generating any. They why they do more than you want, and break developer flow.
The bottleneck isn’t “agent intelligence.”
It’s speed, context retrieval and the irrelevant code that gets shoved into the prompt.
Most agent stacks today are basically sequential grep pipelines:
It’s slow, noisy, and compounds latency every step.
WarpGrep is built to do that dirty job correctly and fast.
They value human attention.
You can’t build responsive coding agents until retrieval is treated as its own learning and inference optimization problem.
They optimized for a simple goal: keep both the developer and the agent inside the sub-10-second “flow window.” Anything slower and usage collapses.
WarpGrep is an RL-trained retrieval model designed specifically to be used as a tool by a coding agent. It operates under a strict budget:
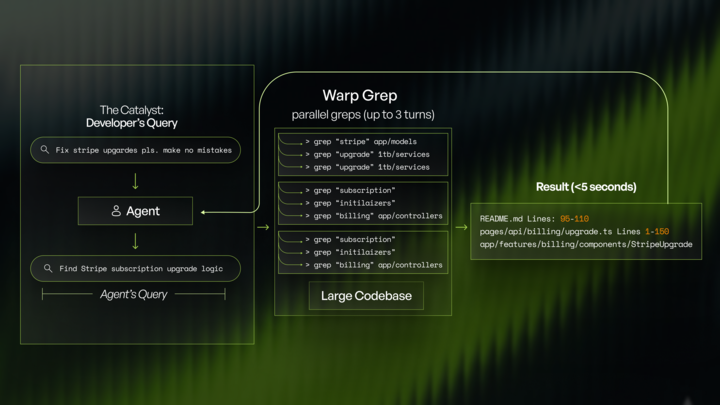
WarpGrep is an expert at deciding what to grep, and what context is relevant for the task. That’s it. This combination reduces context rot by more than fifty percent in production and eliminates the “forty irrelevant files in your prompt” failure mode.
SWE-Grep runs at around 650 tokens per second on Cerebras.
WarpGrep hits around 900 tokens per second on B200.
They worked closely with NVIDIA to optimize WarpGrep. CUDA gives them the stability and customization ability to push non-standard inference workloads for parallel search.
RL for MOEs is notoriously inefficient, so they built infrastructure to eliminate dead time:
Those optimizations delivered a 1.6 to 2.35 times training throughput boost with essentially no sample efficiency loss.
Every company building coding agents is running into the same wall.
Once your agent touches a large codebase, retrieval dominates latency and derails reasoning.
You solve it by giving the agent a retrieval system that behaves like a specialist, not a bottleneck.
If you want an agent that actually performs on large codebases, doesn’t have crippling context rot, and stays within real-time latency, reach out!
https://docs.morphllm.com/api-reference/endpoint/mcp
https://docs.morphllm.com/sdk/components/warp-grep
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Built for Delaware C-Corps. Trusted by 2,000+ startups.
Copyright © Fondo (BloomJoy, Inc.)




